

Here’s a brief summary of recent research undertaken jointly by TCS Research and IIITH in the Embodied AI space.
Autonomous vehicles, drones and humanoid robots may once have been confined to the science-fiction realm but today they are a reality. They are examples of embodied artificial intelligence which interestingly enough can be traced back to the 1990s. The idea stems from the fact that machines can engage and interact with their environments and learn through trial and error. Currently, robots are getting deployed to work with humans in various industrial scenarios like retail, smart manufacturing and more. “In this setting, robots need to learn new skills from humans dynamically, understand the context of work and instructions from humans, learn and plan tasks in sync with human activities so that they can augment the human workforce to increase their productivity,” explains Dr. Brojeshwar Bhowmick, Principal Scientist, TCS Research. From this point of view, Prof. Madhava Krishna, Head of the Robotics Research Centre and the Kohli Center for Intelligent Systems, remarks that the agents are expected to quickly learn and adapt to new settings, tasks and requirements of humans without extensive retraining and going back to the drawing board. “They are also expected to be equipped with a diversity of skills in task execution and an ability to breakdown the overall task into sub tasks and actions,” he says.
LLM-Guided Interactions
In 2022, collaborative effort between TCS Research and IIITH analysed a variety of problems in this domain. Some of the recent accomplishments include LLM-guided anticipation, planning, collaboration and knowledge expansion in a human-robot interactive setting. In the context of household environments, the TCS-IIITH team evaluated an assistive agent’s ability to anticipate future tasks and become more efficient by planning both its current and future tasks. The robot does this by leveraging LLMs which have the ability to learn user task patterns from a few in-context examples given a partial routine or specific user preference. For instance, if the task presented is to ‘heat milk’, the agent will anticipate the next task too which is to ‘serve the milk’ to the human. “This way, the robot can plan its trajectory around the kitchen such that when it goes to pick up a mug to heat milk in, it will simultaneously pick up a tray to serve the mug on,” explains Prof. Krishna. The research resulted in a paper titled, “Anticipate and Act: Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments” that was presented at the 2024 IEEE International Conference on Robotics in Yokohama, Japan. It demonstrated a 31% reduction in execution time in comparison with a system that does not consider upcoming tasks. “While the framework allows the robot to predict upcoming tasks based on what it has seen before or based on its interactions with the human helps it in planning its tasks, it also allows the robot to recover and rearrange its sequence of planned tasks in the event of the human asking for something different and totally novel,” says the professor.
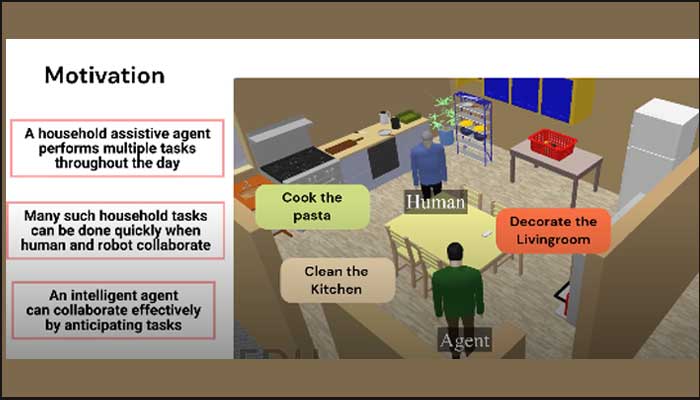
Adapting To The Unexpected
The next agentic refinement by the researchers in the household setting came about with the initial assumption that when a household assistive agent is required to perform multiple tasks throughout the day – from cooking and cleaning to other tasks such as decorating the living room etc – the tasks can be completed quickly with human-robot collaboration. “There are no instructions for the agent in this scenario. The agent learns about the failure probability of the human thanks to the interactions it has had, anticipates scenarios and acts by adapting itself accordingly. For example, if the joint task that the human and the robot are expected to accomplish is serving of breakfast which includes boiling an egg and pouring juice, the typical way in which collaboration will unfold is with the agent boiling the egg and putting it in a plate while the human takes the plate to the table. In the event of the human picking up only the glass of juice and taking it to the table, the agent will recognise this, immediately replan and retrieve the plate to the table itself. This research on the ability of the robot to adapt itself to an unexpected outcome has culminated in a paper titled,’Anticipate, Adapt. Act: A Hybrid Framework for Task Planning’ which is currently under submission for the upcoming 12th European Conference on Mobile Robots to be held in Italy.

LLM+Knowledge Graph+Human Input
What if embodied agents encounter novel tasks that they are not trained for? Traditionally, this is where LLMs come into play. LLMs trained on a large corpus of data can generate action sequences but they often hallucinate due to lack of domain-specific knowledge resulting in task failures. To counter this, the research team proposed a model which they titled, AdaptBot that uses Knowledge Graphs and human input to correct LLM-generated outputs, thus enabling successful task completion. They illustrated this with the help of a simulation where the robot was presented with the task of preparing an omelette with farm eggs. It resulted in a failure because it couldn’t find “farm eggs” in the environment. When the framework was encoded with a knowledge graph that includes domain-specific knowledge, the system detected that farm eggs are not present and replaced them with the eggs that were available. Similarly when the agent encountered another task failure, it solicited and used human input to refine its existing knowledge enabling it to complete the given task successfully. “Essentially, in this model, we are leveraging LLMs for task decomposition, knowledge graphs for domain constraint refinements and using human input for knowledge expansion,” remarks Prof. Krishna. This interplay of LLM, knowledge graph and human input was successfully demonstrated in simulated settings involving both cooking and cleaning tasks.

Collision Avoidance and Pushing
While the tasks mentioned above were high level frameworks, the research teams have simultaneously been engaged in training the embodied agents low level skills such as collision avoidance (for manipulators), object pushing, object grasping and so on, with the help of Gen AI principles. “On a manipulator which is essentially a robotic arm on a mobile base, we demonstrated motion planning – how it can take objects say, from one shelf of a cabinet and place it on another shelf without colliding with the other objects – thanks to a Guided Polynomial Diffusion (GPD) framework. The latter showed how our manipulators were faster and more successful when compared with SOTA,” explains Prof. Krishna.

Multi-Object Search
Just like the tasks of cooking and cleaning in household environments are high level tasks for embodied agents, so is the concept of multi-object search. The idea behind multi-object search research was to teach agents to learn and generalise finding multiple objects in indoor environments, similar to humans who say, must search for and fetch house keys, umbrella and socks from different locations in their home before heading out for a walk. For this, the team developed a long horizon Reinforcement Learning framework that manages to quickly search for and find more than one object in a sequence agnostic fashion. Prior methods were developed that could handle only one object query at a time or in a pre determined sequence whereas this was the first such method that showed abilities to search simultaneously for more than one object with a generic framework. It not only reduced time taken but also the distance travelled as the agent adapted its explorations based on prior observations. “Further navigation to open set objects based on locating them on 3D SLAM maps have been implemented. Though not part of the proposal they provide for a novel framework to quickly search for object(s) in known/unknown maps and have been shown to work on both the Wheelchair and the Self Driving Car,” remarks Prof. Krishna.

The Road Ahead
“Ideally we would like to accomplish skill generalization for agents,” remarks the professor. He mentions that tasks that can easily be generalized by humans, such as intuitively opening doors or drawers that they haven’t been exposed to earlier are not as straight forward for robots. “Training embodied agents with very little data is now the Holy Grail of robotics. Our aim is also to accomplish generalized zero-shot learning for our models,” says Prof. Krishna. Dr. Bhowmick sums up by stating, “Going forward, we envisage a foundational model for embodied AI which will enable a robot to autonomously learn to adapt to new tasks while the environment, skills and embodiment can change”.

Sarita Chebbi is a compulsive early riser. Devourer of all news. Kettlebell enthusiast. Nit-picker of the written word especially when it’s not her own.
Next post