
From education to entertainment, deep learning technology perfected by researchers at the Centre for Visual Information Technology, IIITH also finds potential in futuristic scenarios involving virtual humans. Read On.
On May 12, 2020, just a little after 8 pm, Google Search reported a surge in queries for the term ‘Atma Nirbhar’. This was in response to the Honourable PM Modi’s address to the nation in which he had proceeded to announce economic initiatives under a fiscal package. It turned out that the speech which was delivered in chaste Hindi had gone over most (Hindi and) non-Hindi speaking heads. Such ‘lost in translation’ moments for a majority of the citizens could have been totally averted if only the speech had been live streamed with automatic translation into any language of your choice.
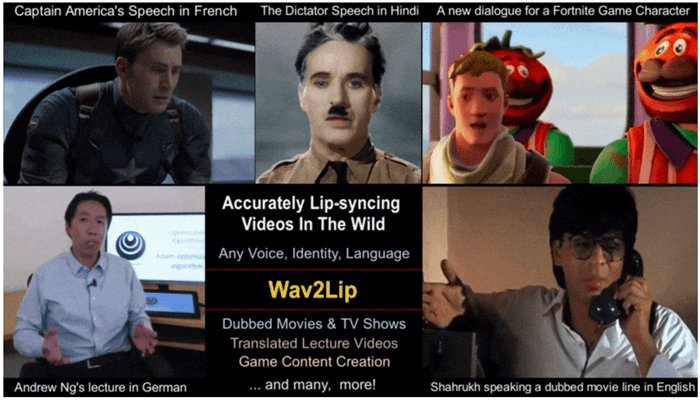
Accurate LipSync
Early this year, Prajwal K R and Rudrabha Mukhopadyay, researchers at the Centre for Visual Information Technology, IIITH under the guidance of Prof. C V Jawahar and Prof. Vinay Namboodiri (University of Bath) attempted to do just that. Using a sophisticated AI framework, their technique enables one to synchronise lip movements of a person in a video to match it with any audio clip. Previously, accurate lip movements could be produced only on static images or videos which had minimal head movements. In a real world scenario, the setting is much more dynamic and unconstrained. Hence, significant parts of the generated videos used to be out-of-sync with the new audio. A video where the lips are not in sync can be annoying as hell and completely ruin the viewing experience. In fact research has shown that a viewer can recognize an out-of-sync video segment as small as just ≈ 0.05−0.1 seconds in duration. Even in interactive communication such as video conferencing and television broadcasting, seamless lip sync has often been underscored. To the extent that several standardization bodies have recommended that the differential delay between audio and video should remain below certain thresholds.
Aiding Education
The AI model created by the IIITH team can be applied to create videos of any face, in any voice or language throwing open endless possibilities. While the implications for entertainment are mind boggling, there’s something even more close to Prof. Jawahar’s heart which has spurred this particular research in the first place. That of using AI in the context of education. With his vision of easy availability and access to educational online content to all, the professor is of the opinion that language should be the least of the barriers to gaining knowledge. Thanks to this technology, well-made lectures by prominent professors or experts on certain topics can be translated into any language of your choice. Or better still, highly accented English videos themselves can be recreated into an accent more comprehensible to the Indian populace (think Indian English!). In the current context of a wholesale virtual education across the country, the technology has the potential in making education more inclusive especially for rural students. In situations where there’s low internet bandwidth and other connectivity issues, lessons with only audio content can be streamed while the AI algorithm could generate the corresponding video accurately matching the original audio. Such a novel approach can make the learning experience a fulfilling one. In a world where online interactions are the new normal, the researchers foresee its applications in video calls and conferencing where the tech comes to the rescue in case of video glitches. That is, if the incoming video signal is lost, the AI model can automatically plug in a synthetic video with accurate lip sync, enabling the work-from-home situation.
Media Magic
Popular or critically acclaimed movies of any language as well as other forms of entertainment have traditionally been accessible thanks to a combination of dubbing and the use of subtitles. But now with AI entering movie-making, those mismatched lip movements and distracting subtitles will give way to an enhanced viewer experience. However, aside from recreating and translating talking face videos of real persons, the technology can be applied to do the same for animated images. In the realm of game development, this will not only significantly reduce time and effort taken to correct lip movements of the game characters to match dialogues, but also open other possibilities for creating riveting games. You can now have your in-game character speak whatever you are saying. Imagine playing PUBG and having Carlo moving his mouth and lips to exactly match what you say during the game play! This leads to a significantly more immersive gaming experience itself. Likewise social media tools such as GIFs can get a makeover with corresponding lip movements that will enrich interactivity. For instance, a perfectly mouthed “Whatever” accompanying the eye-roll is a greater value-add than a mere eye-roll running in a loop.
The Future
Moving beyond education and entertainment, the machine learning technology of Wav2Lip has implications in other upcoming areas as well. One of the most interesting ones is in its application in the enhancement of AI chatbot avatars or the computationally created virtual humans such as that recently unveiled by STAR Labs CEO, Pranav Mistry at the annual Consumer Electronics Show this year. Unlike the virtual assistants such as Siri and Alexa, these avataars are envisaged to be life-sized human interfaces with technology. So rather than play a song that you requested for or rattle out the weather for the day, these virtual humans are designed to converse and interact as lifelike companions in various real situations – at the bank, in a restaurant, at the airport and so on. Having these AI-powered lifeforms talk to you in any language in the most natural manner, with perfect lip movements et al could create a whole new reality.
Here’s a demo video:
For more information on the research, please refer to the paper: https://arxiv.org/abs/2008.10010
For code and models, please go to: github.com/Rudrabha/Wav2Lip

Sarita Chebbi is a compulsive early riser. Devourer of all news. Kettlebell enthusiast. Nit-picker of the written word especially when it’s not her own.
Next post