

When Angel Games created the popular ‘drawing and guessing’ game of Pictionary, little did he know that the innocuous fun game often used to build creativity, communication and team collaboration skills would not only inspire the creation of agents who could play it as convincingly as humans but also establish a benchmark for novel multi-modal AI agents.
What began as an endeavour to have a computer program playing Pictionary just like a human has resulted in a paper titled, “Sketchtopia: A Dataset and Foundational Agents for Benchmarking Asynchronous Multimodal Communication with Iconic Feedback,” authored by Prof. Ravikiran Sarvadevabhatla, IIITH and his MS by Research student, Mohd. Hozaifa Khan. “It was always a dream that someday we will have Pictionary-playing agents”, says Prof. Ravi Kiran Sarvabhatla tracing the genesis of his research to his PhD thesis while at IISc. While the technology did not exist back then to pull it off, the professor also realised the deeper implications behind what may seem like a fun game. “In AI, there has been a history of games being used as a proxy to see how far AI has advanced,” he remarks, listing out computer programs – AlphaGo and Deep Blue – that were developed for playing the board game Go and Chess respectively.
Dataset and Bots
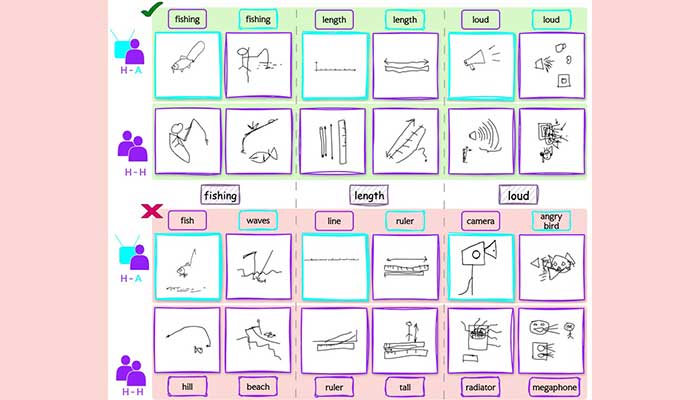
With the goal of creating human-like and relatable agents who could demonstrate a wide range of behaviours from excellent drawing and guessing skills to average or below average abilities, the researchers trained their agents on real-life, authentic Pictionary games – over 20,000 sessions that captured more than 2,60,000 hand drawn sketches, 10,000 erases, 56,000 guesses, and 19,000 feedbacks. In addition to this, they also collected 800 human-AI sessions where players unknowingly interacted with AI agents allowing for the study of human-AI interaction dynamics. This curated dataset, which they call Sketchtopia, led to the development of two foundational AI agents – DRAWBOT, that uses a stable diffusion model and GUESSBOT, that employs a retrieval-based approach – to draw and guess the figures drawn respectively. Since the goal is to make the gameplay as human-like as possible, the retrieval-based approach accommodates human quirks such as overlooking spelling errors; spyder for spider and so on.
Seamless Interaction Is Key
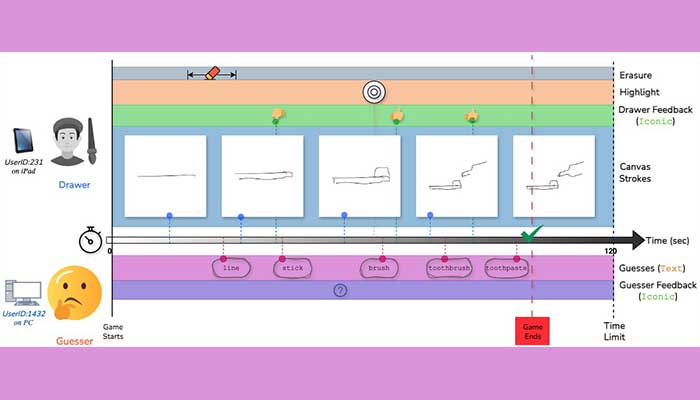
What makes these gameplay sessions so human is the smooth flowing nature of the play itself. The guesser does not have to wait until the drawer completes making a sketch in order to begin guessing; there is a considerable amount of overlap in interactions. It was this asynchronicity that made the researchers realise that they could use it for something bigger. “If you look at LLMs today, say, ChatGPT, the interaction is based on turn-taking which means that you first type something, wait, and then it provides a response. But human interaction is not like that. If you interrupt me while I’m talking, I will still understand what you are saying. Even if you don’t interrupt me but nod your head, there is feedback that you are processing what I’m saying. It is asynchronous in nature,” explains Prof. Sarvadevabhatla.”
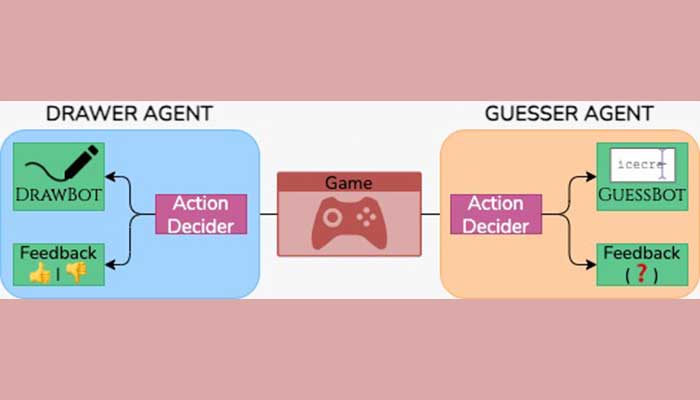
Mohd. Hozaifa further expands by saying, “One of our primary goals was to demonstrate a more fluid and natural communication interface for AI, using the game of Pictionary as a practical testbed. Unlike the rigid, turn-taking systems prevalent in current AI interactions (such as ChatGPT), our setup allows for interruptions, dynamic decision-making on actions, and flexible action execution. This showcases that ChatGPT represents just one form of AI interaction. We’ve successfully demonstrated a more collaborative, natural and interactive communication paradigm with AI, highlighting the immense potential for future AI interfaces.” With this future in mind, the team introduced metrics that could evaluate and benchmark LLMs for asynchronous interaction.
Challenges in Agent Development
Speaking about the issues the researchers faced, Mohd. Hozaifa candidly remarks,”Our initial attempts at building AI agents faced significant hurdles. We struggled to achieve satisfactory results due primarily to a lack of mature research and specialized tools in the field. It felt as though we were waiting for foundational advancements in key areas before our agents could truly perform.” Luckily for them though, the field of AI progressed rapidly enough. “We pivoted to leverage cutting-edge models and research works such as CLIP, Stable Diffusion, and control techniques like LoRA and T2I Adapters. This shift allowed us to successfully develop our functional Agents,” he says.

CVPR 2025
This novel research was presented at the prestigious Computer Vision and Pattern Recognition (CVPR) Conference 2025 in Nashville, US. “We had good response at the conference. Apart from interest generated from the fact that we had agents drawing and guessing at a game, everyone liked the idea of the game itself being used to benchmark a multi-modal capability that does not fully exist today,” remarks the professor. While the next generation of voice assistants do possess some asynchronous functionality, they possess only a single modality. In this case, the agents are multi-modal in nature, incorporating drawing as well as guessing elements in the mix. According to Mohd. Hozaifa, the multi-modal dataset garnered significant interest, with various aspects appealing to different audiences. “Some researchers focused on its multi-modality, while others were particularly interested in the temporally language-grounded sketch dataset or in next-stroke prediction. However, the overarching interest converged on our core objective: enabling asynchronous communication.” Currently, the team is open to offers from gaming companies to license and market the technology.
For more information about the work, click here.

Sarita Chebbi is a compulsive early riser. Devourer of all news. Kettlebell enthusiast. Nit-picker of the written word especially when it’s not her own.
Next post