
Imagine Greta Thunberg’s impassioned speech at the UN Climate Change Conference translated into Assamese, Telugu, Marathi and other languages for regional viewers. Well, it could soon be a possibility thanks to IIITH’s Machine Learning model that can automatically translate a video of any person speaking in one language to another. Read On.
Content is king. And video content undeniably reigns supreme. If statistics are any indication, it’s not just the phenomenal growth in Internet penetration but also smartphone usage that has led to India leading in YouTube video consumption with currently over 265 million active users. According to YouTube, in 2019 the Indian market witnessed over 95% of online video consumption in regional languages. The Director of Content – Partnerships at YouTube India had remarked to The Economic Times then that the company had always believed that consumers love to watch content in their own language. While echoing this view, Prof. C. V. Jawahar, Dean (Research and Development), at the International Institute of Information Technology, Hyderabad says that though people are consuming video content, available Indian language video content is low, with useful or educational content even lower.

Automation Is Key
As with most research churned out in IIITH’s labs, focus on societal impact has been the driving force. Much of the inspiration stems from Prof. Raj Reddy, Turing award winner, one of the pioneers of AI, the founding director of the Robotics Institute at Carnegie Mellon University and also the chairman of IIIT Hyderabad Governing Council. Prof. Reddy has always envisioned information reach even in the remotest of rural areas. And the idea behind the latest face-to-face translation research is to enable automatic video content generation at scale.
Prof. Jawahar says, “Manually creating vernacular content from scratch, or even manually translating and dubbing existing videos will not scale at the rate digital content is being created. That’s why we want it to be completely automatic. We want the right educational content to reach the rural masses. It could be ‘How To’ videos in sectors such as agriculture, ‘How To Repair or Fix’ things and so on. But this may take time, so we thought why not start with entertainment, like movies and TV shows? Once we have the right framework in place, it’s easy to create other content.” Towards this end, Prof. Jawahar and his students Prajwal K. R, Rudrabha Mukhopadhyay, Jerrin Phillip, Abhishek Jha, in collaboration with Prof. Vinay Namboodiri from IIT Kanpur worked on translation research culminating in a research paper titled ‘Towards Automatic Face-to-Face Translation’ which was presented at the ACM International Conference on Multimedia at Nice, France in October 2019.
What It Is
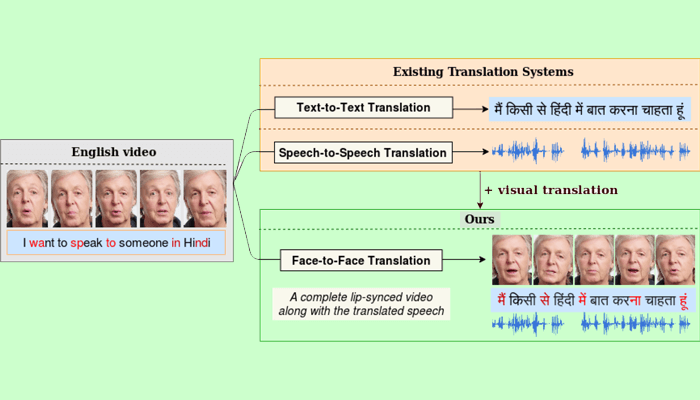
Explaining how machine translation has evolved over the years, Prof. Jawahar says, “Earlier when we spoke about automatic translation, it used to be text-to-text, then came speech-to-speech translation. In this research, we have gone further by introducing a novel approach to translating video content, known as face-to-face translation.” Currently, translation systems for video content generate a translated speech output or textual subtitles. “They do not handle the visual component. As a result, when such translated speech is overlaid on the video, the lip movements are typically out of sync with the audio,” say Prajwal and Rudrabha. An out-of-sync dubbed movie or other video content ruins the viewer’s experience. The research team has built upon the speech-to-speech translation systems and developed a pipeline that can take a video of a person speaking in a source language and deliver a video output of the same speaker speaking in a target language such that the voice style and lip movements match the target language speech.
![]()
![]()
How It Works
Given any video of a person speaking, there are two major components that come into play for translation purposes: visual and speech information. In the face-to-face translation model, speech is translated in the following way:
- The system first transcribes the sentences in the speech using automatic speech recognition (ASR). This is the same technology that is used in voice assistants (Google Assistant, for example) in mobile devices.
- The transcribed sentences are translated to the desired target language using Neural Machine Translation models.
- The translated text is spoken out using a text-to-speech synthesizer. This is again the same technology that digital assistants use to provide voice results.
To obtain a fully translated video with accurate lip synchronization, the researchers introduced a novel visual module called LipGAN. This can also correct the lip movements in an original video to match the translated speech obtained above. For example, badly dubbed movies with out-of-sync lip movements can be corrected with LipGAN. What makes LipGAN unique is that since it has been trained on large video datasets, it works for any voice, any language and any identity.
Multi-pronged Approach
While this technology is designed to handle videos in natural and uncontrolled settings, it works best for videos with minimal head movements of speakers. “A lot more challenges come into play when the faces are moving,” says Prajwal. An extension of the project seeks to address these challenges as well as those of creating different language versions of educational content videos with minimal effort. For example, creating a Hindi video from a 1-hour English video with say, 1.5 hours of effort. “This would perhaps be the more practical middle-ground where there is a blend of single-level manual editing, coupled with machine learning,” says Prof. Jawahar.
Typically, research in the areas of speech, text and facial recognition (or identification of lip movement in this case) are handled by independent communities. “With the proliferation of AI, sophisticated techniques are converging and hence one finds an integrated project of this kind today which would not have been possible, say 10 years ago,” he says. While the team’s primary strength has been LipGAN, special mention must be made of their Indian language machine translation models too. A comparative analysis of their tool vis-a-vis Google Translate for English-Hindi machine translation found the in-house tool to be more accurate.
Digital Alteration
While image and video manipulation have long existed, it was largely confined to movie studios and production houses. With emerging sophisticated AI, it is now more and more possible to create realistic-looking and sounding fake videos, known as deepfakes. While acknowledging that AI can be used with malicious intent, Prof. Jawahar says, “Active research is being conducted to recognize such altered content, and to legally prove that they are fake”. Referring to the institute’s past research on detecting altered images, he says that only the collective effort of responsible use, strict regulations, and research advances in detecting misuse can ensure a positive future for this technology. For now, the application of these innovative techniques that use these tools for educational and assistive purposes is positive and exciting.
Applications
Apart from making content such as movies, educational videos, TV news and interviews available to diverse audiences in various languages, there are potential futuristic applications such as cross-lingual video calls, or the ability to have video calls in real-time with someone speaking a different language. Prof. Jawahar also draws attention to perhaps a simpler, pressing need today – the ability to translate English video content into Indian-accented English. “There are superbly created videos on various topics by MIT and other prestigious institutions which are inaccessible to a larger Indian audience simply because they cannot comprehend the accent(s). Forget the rural folks, even I won’t understand!”, he quips. In addition to translation, the talking face generation approach also comes in handy to animate one’s profile picture that is typically set up for making video calls, enriching the experience of video communication.
In To The Future
Concurring with Prof. Jawahar’s views of increasing the number of videos available in vernacular languages, Prof. Namboodiri says, “Obtaining face-to-face translation is an important aspect that addresses this challenge. However, I would like to point out that the work in solving these problems is not over. When the domains of language, speech, and vision are combined, it results in interesting cases that are not yet solved. For instance, there could be videos where the faces are slightly in profile or when multiple people are talking. We are presently actively involved in pursuing a number of these problems.” Other possible enhancements mentioned by the students include an improvement in each of the individual modules of the pipeline to provide a better quality of generated speech, text and faces. There’s also another unaddressed research problem that arises when the duration of the speech gets naturally modified upon translation. This would require an automatic transformation of the corresponding gestures, expressions, and background content. “The next level of interplay between computer vision (face/lips), speech, and natural language processing (text) will be on expressions in video content. When we translate content, the exact moment when a smile or a frown is appropriate assumes significance,” explains Prof. Jawahar. The group has worked on multiple other closely related projects like lip reading and word spotting in silent videos, lip-to-speech generation, and so on. For hearing impaired individuals, such works are especially invaluable as assistive technologies.
To read more about the research on face-to-face translation, click here.
To view a demo of how it works, click here.
To view the code, click here.

Sarita Chebbi is a compulsive early riser. Devourer of all news. Kettlebell enthusiast. Nit-picker of the written word especially when it’s not her own.
Next post