

Venkata Himakar Yanamandra received his MS Dual Degree in Computational Linguistics (CL). His research work was supervised by Dr. Radhika Mamidi. Here’s a summary of his research work on Towards Sentiment Analysis and Product Identification of Tobacco-Related Text in Social Media:
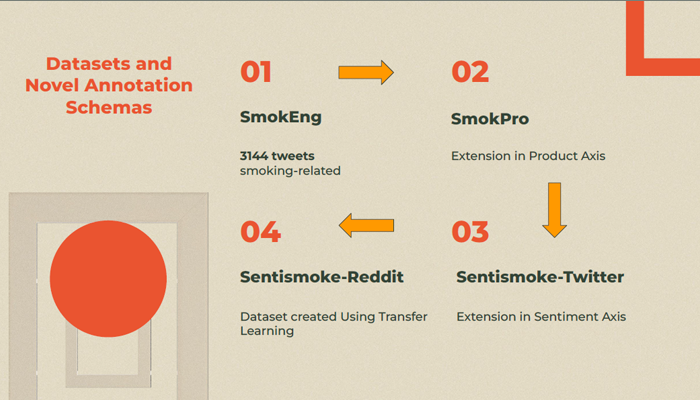
During Covid-19, we have seen experts from various fields come together and collaborate for collective social good. NLP and AI have been employed to create a positive impact in recent years, especially in public health research. In the work-from-home world, 500 thousand tweets are posted every day and 4 petabytes of data is created on Facebook1 . This plethora of data can be utilized for online bio-surveillance to early insights into potential future epidemics. Today, smoking tobacco is one of the leading causes of preventable death. It causes more than 8 million deaths per year worldwide 2 . Real-time monitoring of public sentiment and trends helps us understand the gravity of potential health threats like smoking tobacco and help create necessary cessation and preventive campaigns. Contrary to previous tobacco studies, we have taken the language of the demographic affected, street words, and colloquial slang related to smoking into account. We released the smokeng dataset, a general tobacco-related dataset consisting of 3144 tweets along with a comprehensive annotation schema. Each class is created and annotated based on the content of the tweets such that further hierarchical methods can be easily applied. While cigarette smoking went down among high school students from 2011 to 2019, the number of students using e-cigarettes rose from 3.6 million to 5.4 million 3 . As the e-cigarette problem has exponentially increased, the need to treat smoking products individually presented itself. The target audience varies and might use different language and sentiments to describe the product they use. We extended Smokeng on tobacco product and product sentiment axes to release the SmokPro and SentiSmoke-Twitter datasets along with a comprehensive annotation schema for identifying tobacco products and their respective sentiments.

Contemporary tobacco-related studies are primarily concerned with a single social media platform while missing a broader audience. Moreover, they are heavily reliant on labeled datasets, which are expensive to make. We explore sentiment and product identification on tobacco-related text from two social media platforms. Extending SentiSmoke-Twitter dataset, we created SentiSmokeReddit product and sentiment datasets by the application of transfer learning. To the best of our knowledge, this was first cross-OSM-platform attempt in topical tobacco research using semi-supervised learning. Further, we prove the efficacy of standard text classification methods on the above datasets by designing experiments that do both binary and multi-class classification. We then perform benchmarking experiments using state-of-the-art text classification models including BERT, RoBERTa, and DistilBERT, exploiting contextual word embeddings to prove the efficacy of the dataset and the suitability of the models for the task. This work paves the way for further analysis to understand sentiment or style, making these datasets vital to disease surveillance and tobacco use research.
- https://techjury.net/blog/how-much-data-is-created-every-day/gref
- https://bit.ly/2WOuQki
- https://bit.ly/2UrBnjf