

Dr. Karthik Vaidhyanathan explains a novel approach that allows a system on edge to self-adapt between different ML models, thus achieving better resource efficiency.
Lately, leaps in technological progress have meant that AI is not only popular but is now democratised. Simplistically put, it means that applications like ChatGPT are available or easily accessible to all – even those without specialised tech skills. Historically if one were to look at the field of AI, it has existed since the 1940s and 50s. The obvious limitation then was the lack of sophisticated hardware to perform the computations. Over the last two decades, with the advancements in computing and infrastructure capabilities that grew with the emergence of cloud computing, the field of AI also has progressed rapidly. However along with an improvement in hardware capabilities on one end, on the other, computing started becoming more and more pervasive with a plethora of connected devices (mobile phones, IoT devices, smart watches, etc.). It’s these concerns relating to data privacy, security, resource constraints and latency which demanded attention eventually leading to the emergence of edge AI.

An Edge Over Data Centers
The underlying thought behind the genesis of ‘AI on the edge’ was that a lot of the problems could be solved if one could perform computation at the location where data is gathered or at the source of data itself rather than sending it anywhere else. One problem that can be addressed is that of data privacy with data stored on your device itself. The second relates to latency, because now you can get immediate responses without waiting for long. The third aspect is that of sustainability. From an energy consumption angle, as per studies conducted, data centres consume roughly 1-2% of global electricity and account for about 2- 4% of global carbon emissions. Hence having ML models on the edge or on devices is the need of the hour. We see this on our phones with multiple AI models already in operation, like facial recognition or classification of photographs in the Gallery based on events and so on, which require ML models in place. As researchers working in the intersection of software architecture and ML, we are constantly trying to improve the efficiency and effectiveness of such ML systems. One way we attempted to do this is via a self-adaptive mechanism which selects the right model to process data based on user demand and resource constraints. This concept stems from our research on self-adaptive ML-enabled systems 1 which proposes the use of a model balancer that switches between machine learning models considering operational context and environment such as number of user requests, response time of models, accuracy, energy consumption 2 , etc.
1 Towards Self-Adaptive Machine Learning-Enabled Systems Through QoS-Aware Model Switching -https://arxiv.org/abs/2308.09960
2 EcoMLS: A Self-Adaptation Approach for Architecting Green ML-Enabled Systems https://arxiv.org/abs/2404.11411
Switching For Efficiency
Typically, there’s a trade-off between latency and accuracy of predictions of an ML model; the more accurate the prediction, the longer the time taken for processing but there are scenarios when lighter models can offer higher accuracy with lower latency. In lieu of creating a single lighter model or a heavier one, our solution looks at the context and then decides whether to use a heavy ML model vis a vis a lighter model. To illustrate how this works, consider a phone camera that is being used to monitor crowds. If the number of people is very high at a given point in time, you would probably require a sophisticated and highly accurate model that is ‘heavy’. But if there is no one around, you could probably use a smaller model that consumes less battery power, and processes data faster. The concept is that of a ‘model balancer’, that is, if you have a suite of ML models performing the same task, the system intelligently switches between models based on the input that is coming in. When this is done, it can improve accuracy, save cost, and improve response time, thus striking a balance between the critical parameters. We have developed a suite of algorithms that can achieve this including clustering-based ones, epsilon greedy, etc which allows us to have a trade-off between accuracy and response time/energy consumption. Based on this concept, that has been published in various top-tier international conferences, we have also developed an exemplary tool that researchers and practitioners can use. It is called Switch which aims to provide an ML system with the ability to autonomously adapt to different scenarios through model switching .

Prototyping On the QIDK
For developing the self-adaptive mechanism, we had picked computer vision as the application domain. This was partly due to the fact that we were working on developing a crowd monitoring solution in the Smart City Lab. We were able to successfully apply our model balancer concept to computer vision domain. This is now being extended to different natural language processing domains, or even regression domains which require numerical predictions like those used for predicting the weather. In a crowd monitoring situation with dense crowds, a mobile camera or drones capturing data is a more efficient way of analysing crowds. When we began exploring the model-switching mechanism on smartphones, coincidentally Qualcomm, which has been a pioneer in the edge domain, came up with the Qualcomm Innovators Development Kit (QIDK). The kit is a SnapDragon mobile platform enabling developers to build prototypes for a variety of applications. We developed an Android app based on our model balancer concept and deployed it in the QIDK obtaining promising results. The kit performed about 10x faster in terms of processing compared to some of the state-of-the art devices out in the field thanks to its dedicated hardware accelerator and GPU. It was thanks to Qualcomm that this work was also presented during the Qualcomm University Platform Symposium and was highlighted during the Qualcomm developer conference in April 2024.
Onward and Forward
Currently, one of the biggest challenges in software engineering is software sustainability. Edge computing can play a big role there but even that needs to be sustainable. One aspect to that is energy consumption of the device itself. Regardless of the device one is using, no one wants its battery to drain out soon. We also want to be mindful of the carbon emissions of the software on the edge considering that at present software emissions equate to the carbon emissions of rail, air and shipping combined. Another dimension is that of technical sustainability which is about how maintainable the system is. Over a longer period of time, we will have a large number of models of several different types in the system worked upon by different individuals and the system must continue to seamlessly switch between different models. In order to enable this, we need more work to be done on the EdgeMLOps side.
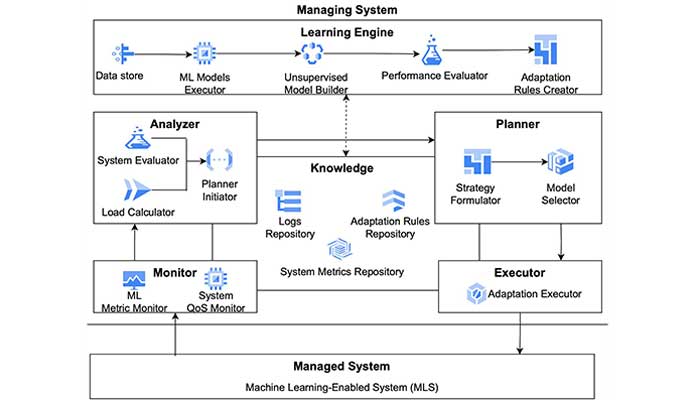
We also need to look into the economic angle of sustainability. Running on edge might be cheaper compared to cloud depending on a given operational scenario. With the support of Qualcomm Edge AI Lab, our group is working strongly towards the goal of sustainability from all these angles. In this direction we are also collaborating with Dr. Suresh Purini to integrate the notion of model balancer with the framework that was developed by his research group for large scale CCTV camera analytics. In addition to this, another compelling research angle that is being actively explored is this notion of edge cloud continuum where switching between the cloud and the edge itself can be performed based on the energy, performance and its subsequent trade-off. We may want to process data on our phones and that is highly effective but sometimes we may need the power of the cloud instead and this sort of self- adaptation by the edge system is perhaps one of the ways forward.
This article was initially published in the June edition of TechForward Dispatch

Dr. Karthik Vaidhyanathan is an Assistant Professor at the Software Engineering Research Center, IIIT-Hyderabad, India where he is also associated with the leadership team of the Smart City Living Lab. His main research interests lie in the intersection of software architecture and machine learning with a specific focus on building sustainable software systems in the cloud and the edge. Karthik also possesses more than 5 years of industrial experience in building and deploying ML products/services. Karthik is also an editorial board member of IEEE Software. https://karthikvaidhyanathan.com
Next post