

Prof. Madhava Krishna briefly explains the way IIITH’s self-driving car works and what is novel about it. This is an edited excerpt the TechForward research seminar series.
IIIT Hyderabad’s Self Driving Car is an electric vehicle that performs point to point Autonomous Driving with collision avoidance capabilities over a wide area. Equipped with 3D LIDAR, Depth Cameras, GPS systems and AHRS (Attitude and Heading Reference System which essentially means sensors on three axes to estimate it’s orientation in space), the car can also accept Open Set Natural Language commands and follow those commands to reach a desired destination. SLAM-based point cloud mapping is used to map the campus environment and a LIDAR-guided real-time state estimation allows for localization while driving. Trajectory optimization frameworks a-la Model Predictive Control provides for real-time rollout of optimal trajectories. Such trajectories can be initialised with data-driven models for faster inference time optimization. A number of publications in high-profile venues and highly competitive conferences decorate the research landscape of Autonomous Driving research at the International Institute of Information Technology, Hyderabad, Gachibowli Campus.
Open Set Navigation
To better understand open set navigation commands, let’s first consider how humans often navigate – with minimal map usage, relying on contextual cues and verbal instructions. Many navigation directions are exchanged based on recognizing specific environmental landmarks or features, for example, “Take right next to the white building” or “Drop off near the entrance”. In a parallel context, autonomous driving agents need precise knowledge of their pose (or localization) within the environment for effective navigation. These are typically achieved using high-resolution GPS or pre-built High-Definition (HD) Maps like Point Cloud, which are compute and memory-intensive.
Alternatively, many efforts utilise open-source topological maps (GPS-like Maps) for geolocalization, like OpenStreetMaps (OSM), as a lightweight solution. However, they are metrically inaccurate (~6-8 meters) and suffer localization errors when navigating to arbitrary destinations within the map. Moreover, some environmental landmarks, such as open parking spaces, may not be marked in OSM maps due to their dynamic nature. Thus, at IIITH, we are interested in exploring a feasible and scalable method to localise using solely real-world landmarks, akin to human navigation.
IIITH’s Efforts
We intend to address it by exploiting foundational models that have a generic semantic understanding of the world which can be distilled for downstream localization and navigation tasks. This has been achieved by augmenting open-source topological maps (like OSM) with language landmarks, such as “a bench”, “an underpass”, “football field”, etc. which resemble the cognitive localization process employed by humans. These enable an “open-vocabulary” nature that allows navigation to places for which the model is not explicitly trained, leading to a zero-shot generalisation to new scenes. The RRC Autonomous Driving group- AutoDP at IIITH demonstrates an attempt to integrate classical methods with post-modern solutions in open-world understanding, bringing the best of both worlds to solve the ever-challenging task of precise localization and navigation with real-world deployment through the in-house developed prototype.

Differential Planning
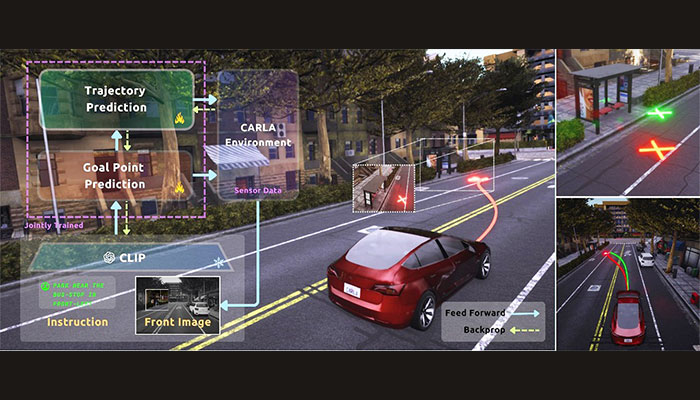
Mapping, localization, and planning form the key components in the Autonomous Navigation Stack. While both the modular pipeline and end-to-end architectures have been the traditional driving paradigms, the integration of language modality is slowly becoming a defacto approach to enhance the explainability of autonomous driving systems. A natural extension of these systems in the vision-language context is their ability to follow navigation instructions given in natural language – for example, “Take a right turn and stop near the food stall.” The primary objective is to ensure reliable collision-free planning. Traditionally, upstream predictions and perception are customised for improving the downstream tasks, which is typical in current Vision-Language-Action models and other existing end-to-end architectures. However, prediction and perception components are often tuned with their own objectives, rather than the overall navigation goal. In such a pipeline, the planning module heavily depends on the perception abilities of these models, making them vulnerable to prediction errors. Thus, end-to-end training with downstream planning tasks becomes crucial, ensuring feasibility even with arbitrary predictions from upstream perception and prediction components.
Our USP: NLP+VLM
To achieve this capability, IIITH has developed a lightweight vision-language model that combines visual scene understanding with natural language processing. The model processes the vehicle’s perspective view alongside encoded language commands to predict goal locations in one-shot. However, these predictions can sometimes conflict with real-world constraints. For example, when instructed to “park behind the red car,” the system might suggest a location in a non-road area or overlapping with the red car itself. To overcome this challenge, we augment the perception module with a custom planner within a neural network framework. This requires the planner to be differentiable, enabling gradient flow throughout the entire architecture during training which eventually improves both prediction accuracy and the planning quality. This end-to-end training approach with a differentiable planner serves as the key sauce of our work.
This article was initially published in the October edition of TechForward Dispatch

Prof. Madhava Krishna is Professor and Head of the Robotics Research Centre and the Kohli Center for Intelligent Systems (KCIS) at IIITH.
Next post