Urmi Ghosh received her MS-Dual Degree in Computational Linguistics (CL). Her research was supervised by Prof. Dipti M Sharma.
Here’s a summary of Urmi’s thesis, Dependency Parsing of Bengali-English Code-Mixed Data enhanced with a Synthetic Treebank as explained by her:
Code-mixing (CM) refers to the mixing of various linguistic units (morphemes, words, modifiers, phrases, clauses, and sentences) primarily from two or more participating grammatical systems within a sentence. The development of CM NLP systems has significantly gained importance in recent times due to an upsurge in the usage of CM data by multilingual speakers. However, this proves to be a challenging task due to the complexities created by the presence of multiple languages together. The complexities get further compounded by the inconsistencies present in the raw data on social media and other platforms.
In this thesis, we explore methods to efficiently parse the immensely popular Bengali-English CM which is widely spoken in India and Bangladesh. We present a neural stack-based dependency parser for CM data of Bengali-English by utilizing pre-existing resources for closely related Hindi-English CM as well as monolingual treebanks for Bengali, Hindi, and English. To address the issue of scarcity of annotated resources for the Bengali-English CM pair, we present a rule-based system to computationally generate synthetic CM dataset from parallel treebanks of Bengali and English. The generated synthetic CM data does not require an overhead of preprocessing for language identification and normalization as we get orthographic norms from standard corpora. Next, we project automatic annotations from Bengali and Hindi-English treebanks to Bengali-English using simple heuristics creating a synthetic CM treebank for Bengali-English (Syn-BE). Incorporating Syn-BE into our neural stacking parser further improves its performance. Our final model achieves an accuracy of 89.63% for POS tagging and 76.24% UAS and 61.41% LAS points for dependency parsing. We also present a dataset of 500 Bengali-English tweets annotated under Universal Dependencies scheme which can be utilized for evaluation of the system as well as providing seed training data.
An example of a Bengali-English tweet:

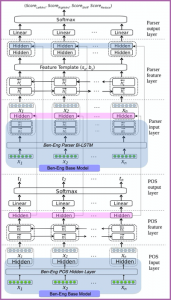
Neural Stacking-based parsing architecture for the joint model for Bengali-English POS tagger and dependency parser: