
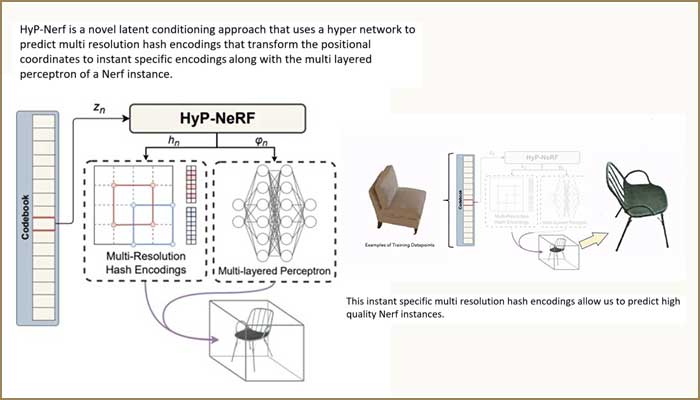
The team used a HyperNetwork to devise a method that can generalise NeRFs.
When a neural network that could represent complex 3D scenes based on 2D images was first developed, it was a revolution in the field of novel view generation which are used in graphics and image-based rendering methods. Traditionally, these models or neural radiance fields (NeRFs) as they are more technically known however have their own limitations, one of them being that they can represent only one 3D scene (which is defined by a bunch of images from different angles) at a time. To represent another 3D scene, a separate neural network needs to be trained. For instance, if there are two scenes, one involving a room with furniture in it and another outdoor scene set in a garden, two different NeRFs are required. In technical terms, NeRFs do not generalise to new scenes. This problem of generalisation has since been researched and improved upon by various groups of the scientific community. At IIITH, a research team comprising Gaurav Singh, Bipasha Sen, Aditya Agarwal, and Rohith Agaram under the guidance of Prof. Madhava Krishna of the Robotics Research Centre and Prof. Srinath Sridhar of Brown University, has created a method enabling generalisation of NeRFs with the help of a HyperNetwork.
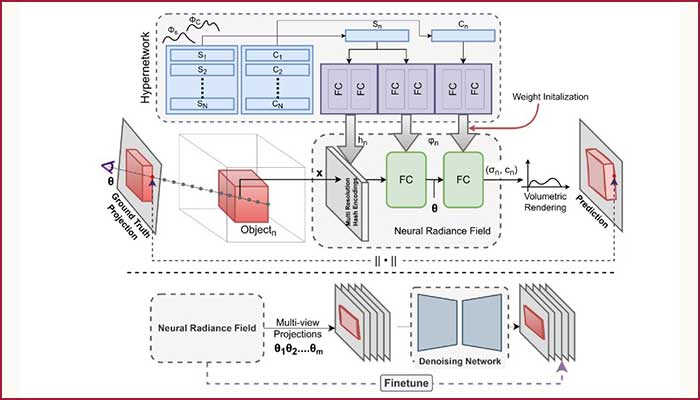
Hyp-NeRF: Trained on 3D images
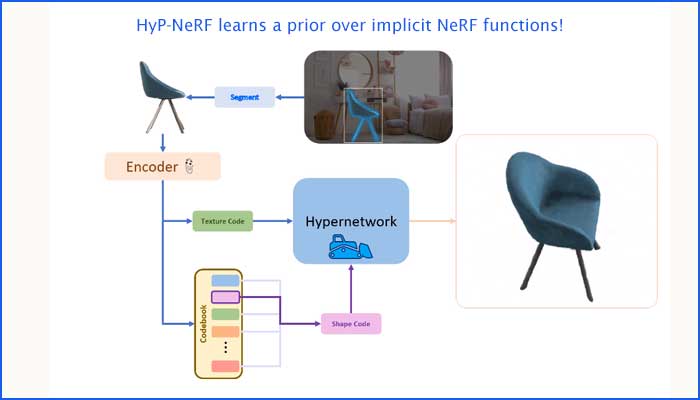
Unlike images that store data exactly the way it is (in the form of raw colour values), NeRFs are more complex because they represent data as weights of a neural network. “It is not a straightforward representation space,” agrees Gaurav Singh, explaining the team’s motivation for exploring how a model could use prior knowledge about the data representation in the NeRF space. The researchers’ quest for creating a model that could create a 3D output with “as little input as possible” led to HyP-NeRF, a model trained through images of 3D objects such as chairs, sofas and cars. With an image of an unseen object or a text as an input, their model uses the learned information to render a realistic-looking image of the object from a different view. The example of an avocado chair – an unseen object in this case – has been elaborated at length on the team’s project webpage where the prompt was for a chair that looked like an avocado in shape as well as in colour. According to the researchers, the high-quality resolution of the output (even higher than the training data itself) is only possible because they operate directly in the NeRF space. “Even when the input image is an occluded one, the resulting output is a detailed and realistic one,” says Gaurav.

Limitless Potential
NeRFs are definitely getting more mainstream and gradually accessible to the general public in industries such as architecture and interior design where rendering of designs and drawings can make the experience more realistic for customers like in the realm of gaming, education (think recreating History in lifelike detail), live events, and robotics. According to Gaurav, “Future methods that learn priors over NeRFs could be used for robotic navigation. For example, if a robot equipped with a camera were to navigate itself around a chair, it can first take 2-3 images of the chair via its camera, process it into a 3D representation and then confidently move around the chair. It can reconstruct an entire 3D scene based on just 2 or 3 views.” Calling it an exciting area to be in, Prof. Madhava Krishna says, “Zero shot NeRF transfer has immense potential in Robotics, both in the context of Navigation, Grasping and Visual Servoing.” Regarding the lead student researcher Gaurav himself, Prof. Krishna remarks that his ability to understand intricate research formulations, concepts and a general sense of research awareness goes much beyond his age. “That coupled with his impressive analytical abilities and rapid coding skills makes him a researcher everyone would be eager to work with.”

The research has resulted in a paper publication titled: HyP-NeRF: Learning Improved NeRF Priors Using A HyperNetwork that will be presented at the 37th Conference on Neural Information Processing Systems 2023 at New Orleans, USA in December. It is a world-class machine learning and computational neuroscience conference that includes invited talks, demos, oral and poster presentations of papers alongside a less formal setting of workshops, and tutorials.

Sarita Chebbi is a compulsive early riser. Devourer of all news. Kettlebell enthusiast. Nit-picker of the written word especially when it’s not her own.
Next post