
At the risk of sounding self-disparaging, we nevertheless begin meetings with the scientific research community by asking them to “dumb down” their research for us. What we essentially mean is of course to explain it such that a layperson with little or no exposure to the Sciences (much less machine learning or deep learning) can get a sense of it. Researchers from the Information Retrieval and Extraction Lab (IREL) at IIITH under the guidance of Prof. Vasudeva Varma have tried to do just that, at least to a limited extent – meet the needs of the journalistic community with the help of an online natural language processing tool. Here’s how.
Automation has not spared the creative sphere and we find robot reporters spitting away articles in international news organizations. Think Cyborg in Bloomberg and the more recent Bertie tested by Forbes. While a machine that generates content mimicking a human does not sound entirely novel, the research team at IIITH comprising of students Raghuram Vadapalli, Bakhtiyar Syed and Nishant Prabhu, in collaboration with Dr. Balaji Srinivasan from Adobe Research have taken a step towards automating science journalism in particular. They have developed an online interactive tool which can automatically generate the title of a blog post when fed the title of a research paper and its accompanying abstract.
 Raghuram Vadapalli
Raghuram Vadapalli
What?
The IREL lab has been dabbling in the area of content repurposing, or transforming content. Researchers here are particularly interested in seeing how content can automatically be published from one platform to another, for example automatically transforming a news article (slightly verbose and lengthy) to fit the style of a tweet (brief and to-the-point) or a Facebook post (short, but engaging) and so on. In the case of their recently published research: “When Science Journalism meets Artificial Intelligence: An interactive demonstration”, the team focussed on transforming a research paper into the title of a blog post.
“Research papers are not accessible to everybody and if they are, they are not easy to read and understand. Typically blogs are written explaining what a specific research paper is about. But it’s not possible to write blogs for every research paper published,”says MS student Nishant Prabhu. As per the team’s literature review, around 2.5 million research papers are published every year. Since writing out a blog post for every such research paper is not manually possible, the idea was to automate this process.
 Nishant Prabhu
Nishant Prabhu
How?
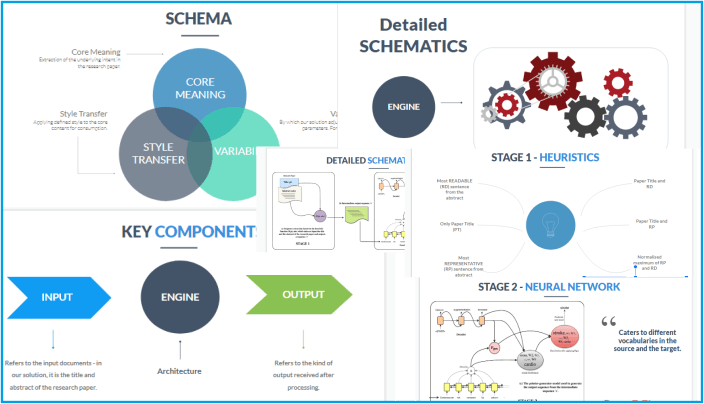
The team used research papers with corresponding popular style blog posts from Science Daily and phys.org, and aimed at generating the blog title. They did this through a two-step process. The first step was to determine the input and for this they fed the paper title and its abstract into a heuristic function to extract relevant information. In the second step, they fed the output of this function into a pointer-generator network to produce a title for the blog post. The pointer-generator network is a hybrid network that was originally showcased at Annual Meeting of the Association for Computational Linguistics (ACL) 2017 and is used in automatic content summarization solutions. “We adapted it to use it for our use-case,” explains Nishant. It scores over other existing networks by not only making it easy to copy words from the source text but also out-of-vocabulary words from the source text. Another advantage was in the elimination of needless repetition of the same words or phrases typically encountered in summarization.
Next Step: Blog Title to Blog Post
For student Bakhtiyar Syed, one of the prime motivations behind the project was to enable scientific discoveries to be easily accessed by the larger public. “Of course, our work has an impact on the way people perceive information. And in this day and age – where there is an ever-growing need for quick information dissemination – research like ours is just a natural consequence of the demand. If our work can aid the task of science journalists, I’d say we have made an impact,” he says.
 Bakhtiyar Syed
Bakhtiyar Syed
The researchers admit that this is just the initial step towards the larger goal of understanding the entire research paper and generating a complete blog. “Procuring data to generate models comes with its own set of challenges. Abstracts are more easily available rather than full paper texts, So while I’m trying with both, successful models are those that use only the abstracts. Currently I’m using the abstract to generate at least the first paragraph of the blog. One step further!,” says Nishant.

Next post