

The Tamil syntactic parser developed by a team of IIITH researchers, is the outcome of a TN-Govt funded project and is based on human annotation of 100K words.
In an advancement that is set to boost Indic machine translation systems, a team of researchers from IIITH led by Prof. Parameswari Krishnamurthy has contributed to the development of a Tamil syntactic parser. The research funded by the Tamil Virtual Academy, an arm of the Information Technology and Digital Services Department, Govt. of Tamil Nadu saw the formal launch of the parser at a special event held on the sidelines of KaniTamil24, an international conference organised for promoting language technology by the TN government.
Automated Understanding Of Language Structure
“Parsers lie at the core of large language models,” remarks Prof. Krishnamurthy, explaining that before a machine can generate a translated text, it needs a thorough understanding of the text itself. This understanding happens via an automatic breakdown of the text (or sentence) into its different components, such as tokenization, parts of the speech identification like the noun, pronoun, adjective, verb, and so on. “There are different kinds of parsers. For instance, the syntactic parser can identify the parts of the speech, their relationships and the overall sentence structure. Then there is the semantic parser where the actual meaning of the sentence is extracted. There is also the discourse parser which understands the structure of discourse in written or spoken language. Our tool, i.e.,the syntactic parser encompasses not just a syntactic analysis but also a morph analysis along with the identification of parts of speech,” she says.
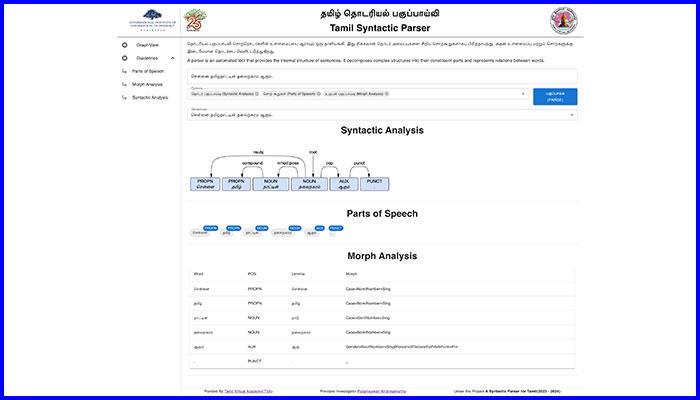
Based On Open Collaboration
With the example of a sentence, “Chennai is the capital of Tamil Nadu”, the research team demonstrates how their parser analyses each word. “ We built the parser based on tree banking using the universal dependency feature,” elaborates Sushvin Marimuthu, one of the team’s researchers, referring to the open community effort consisting of over 200 tree banks in over 100 languages. Stating that such NLP tools will not only help machine translation but also language teaching and testing, the team plans on offering them in the backend for an assistive language learning app. “We are also building automated tools for Tamil as part of the Central Govt’s Bhashini project which is an effort to build different language technology tools,. For that, we are currently exploring how to include the features generated by this parser in building machine translation systems,” states Prof. Krishnamurthy.
KaniTamil24 Conference
The main aim of the conference was to address various aspects of Tamil computing, including NLP, machine translation, LLMs, speech recognition, software development and so on. Hence it was fitting that IIITH’s language technology tool was formally released at the event by the Tamil Nadu IT Minister Dr. Palanivel Thiyagarajan. The IIITH team also presented a paper on ‘Domain Adaptation of Bi-directional Neural Machine Translation (NMT) System Involving Tamil to Telugu’. “We essentially developed domain based NMTs across different domains such as agriculture, health, education, government and science, using generic MT models,” explains Prof. Krishnamurthy. In addition to research paper presentations, a panel discussion was held on the latest advancements in language computing and the requirements for developing the required tools and software. It saw the active participation of Prof. Krishnamurthy who along with the other panellists explored the dynamics of language, technology and ethics. “Everyone on the panel ultimately advocated a regulated and conscientious approach towards AI in linguistics,” she muses.
Video link: Kani Tamil 24 – FFV2
February 2024